Une partie de cet article a été publiée sur LinuxFR.
Après avoir reçu quelques retours, j'ai décidé de publier une version modifiée et améliorée de cet article sur mon blog.
Je remercie donc la communauté de LinuxFR pour ses retours. :D
Les commentaires sur le code ou sur l'article sont les bienvenus.

Le commencement
Actuellement, j'utilise BackupPC pour sauvegarder mes données. BackupPC est un logiciel de sauvegarde qui se connecte à
différents ordinateurs via SSH et utilise rsync pour sauvegarder les données. Il fonctionne parfaitement avec des
ordinateurs Linux et un peu moins bien sur des ordinateurs Windows où il faut installer un rsyncd/Cygwin (les données ne
sont pas protégées par SSH dans ce cas).
Par ailleurs, je développe mon propre logiciel de sauvegarde. C'est un défi
personnel que je me suis lancé pour répondre à mes propres besoins (et aussi pour le plaisir).
Mon premier prototype est écrit en TypeScript et utilise rsync couplé avec Btrfs pour faire des sauvegardes
incrémentales. Malheureusement, quelques problèmes liés à l'utilisation de Btrfs m'ont fait abandonner ce prototype
(problème avec la création d'un grand nombre de snapshots et un système de fichier un peu trop plein). J'en parle dans
un article sur mon blog.
Je me suis donc orienté vers l'écriture de mon propre pool de stockage de données. L'écriture dans ce pool de stockage
m'oblige à écrire mon propre logiciel de synchronisation. BackupPC a fait le choix de rester sur rsync et donc à créer
un fork de rsync capable de se connecter en rsync sur les machines à
sauvegarder, tout en étant capable d'écrire le résultat dans le pool de backuppc, au format de backuppc. Pour ma part,
j'ai choisi de développer mon protocole basé sur GRPC (et donc HTTP/2).
J'ai donc fait un second prototype, toujours en TypeScript, pour tester mon idée. Je suis satisfait du résultat, mais
les limites du moteur JavaScript font de ce prototype un simple prototype. Là aussi, j'en parle dans
un autre article de mon blog.
Je vais donc réécrire la partie la plus importante de ce programme en Rust. Pourquoi Rust ? Dans ma jeunesse (enfin,
j'avais entre 20 et 30 ans), j'adorais programmer en C/C++. Je me souviens d'avoir programmé un petit IDE en C++ avec
Qt. Lors du développement en C++, il m'arrivait parfois de me retrouver avec des fuites de mémoire, des erreurs de
segmentation, ainsi que des problèmes de concurrence d'accès aux données.
C++ m'a beaucoup appris sur le fonctionnement d'une machine, la gestion de la mémoire, la gestion du multithreading,
etc. Tout le monde devrait commencer par ce langage :D.
Rust est un langage qui a été conçu pour éviter ces problèmes. Après avoir lu la documentation, j'ai adoré le concept.
Du coup, j'ai décidé que ce serait une très bonne idée d'apprendre à l'utiliser. (Surtout qu'on en entend beaucoup
parler en ce moment).
Vous trouvez que je digresse beaucoup ? C'est possible.
Revenons à notre programme.
Je me suis dit qu'avant d'écrire la gestion de mon pool de stockage en Rust, je voulais faire un script qui me permette
de migrer le contenu de mon pool de stockage de BackupPC vers mon nouveau pool de stockage. Et de le faire en Rust.
Pour cela, j'ai besoin de comprendre comment fonctionne le pool de stockage de BackupPC. Le faire avec le code source
de BackupPC sera amusant et pas trop compliqué.
Description du pool de stockage de BackupPC

La documentation de BackupPC décrit déjà pas mal de choses :
Ensuite, pour obtenir les détails, il faut aller lire le code source en C qui
sert de liaison avec le code en Perl. BackupPC est originellement écrit en Perl (entièrement, si je ne me trompe pas,
pour la version 3). La version 4 a été partiellement réécrite en C pour la partie qui gère le pool de stockage. Cette
partie est utilisée par le rsync modifié et par la partie Perl à travers la bibliothèque de bindings.
La constitution du pool
Le pool de stockage de BackupPC est principalement constitué de plusieurs dossiers :
Le format des fichiers compressés
Voici la description du fichier compressé selon la documentation (traduction libre) :
Le format de fichier compressé est généré par Compress::Zlib::deflate avec une modification mineure, mais
importante. Comme Compress::Zlib::inflate gonfle entièrement son argument en mémoire, il pourrait consommer de
grandes quantités de mémoire s'il décompressait un fichier très compressé. Par exemple, un fichier de 200 Mo de 0x0
bytes se compresse à environ 200 Ko. Si Compress::Zlib::inflate était appelé avec ce seul tampon de 200 Ko, il
aurait besoin d'allouer 200 Mo de mémoire pour retourner le résultat.
BackupPC surveille l'efficacité de la compression d'un fichier. Si un gros fichier a un taux de compression très élevé
(ce qui signifie qu'il utilisera beaucoup de mémoire lorsqu'il sera décompressé), BackupPC appelle la méthode flush(), qui
termine proprement la compression en cours. BackupPC commence alors une nouvelle section et ajoute simplement le
fichier de sortie. Ainsi, le format de fichier compressé de BackupPC est une ou plusieurs sections/flushes
concaténées. Les ratios spécifiques que BackupPC utilise sont que si un morceau de 6 Mo se compresse à moins de 64
Ko, alors un flush sera effectué.
Donc, dans notre cas, nous devons être capables de lire un fichier compressé comme une suite de fichiers compressés
concaténés les uns après les autres.
Le format des fichiers d'attributs
Dans la documentation, il est expliqué que
dans la version 4, on retrouve un fichier attrib_33fe8f9ae2f5cedbea63b9d3ea767ac0 dans les différents dossiers de la
machine (__TOPDIR__/pc/host1).
Le nom du fichier contient le hash du fichier d'attributs que l'on peut retrouver dans le pool de stockage.
Pour accéder à un fichier du pool de stockage, il faut aller dans le dossier __TOPDIR__/pc et lire le nom du fichier
d'attribut pour retrouver le hash du fichier compressé correspondant au nom du dossier que l'on veut lire. Enfin, il
faut lire le fichier compressé pour obtenir les données.
Le contenu du fichier d'attribut n'est pas décrit. Cependant, on peut le retrouver dans le fichier
bpc_attribs.c.
Le fichier d'attribut est encodé en binaire. Il s'agit d'une suite de varint (entier encodé sur un nombre variable
d'octets).
Un Varint est un entier qui est encodé sur un nombre variable
d'octets. Le premier bit de chaque octet indique si l'entier est terminé ou s'il faut lire un autre octet. Le reste des
bits de l'octet représente l'entier.
Voici une représentation d'un Varint depuis Wikipedia :
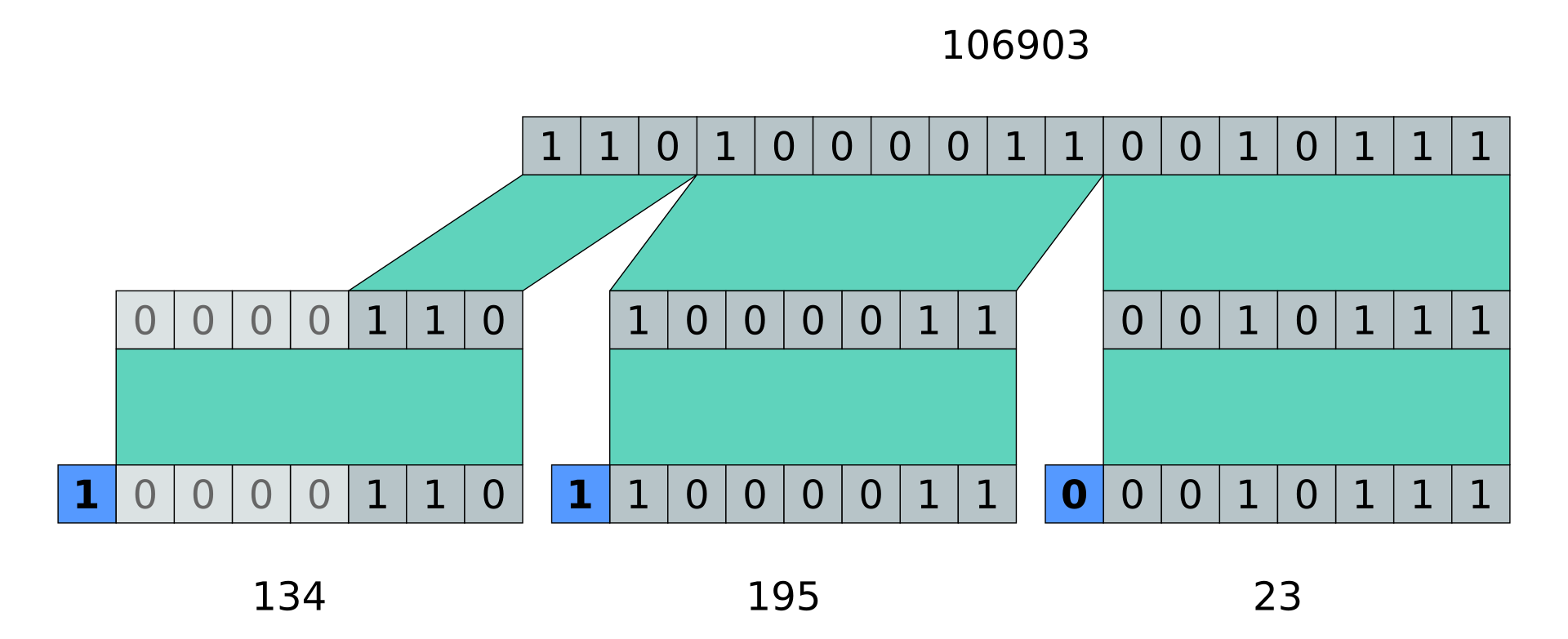
D'après le code source de BackupPC, le fichier d'attribut est encodé de la manière suivante :
Le fichier commence par un numéro magique 0x17565353. Ensuite, pour chaque fichier, on retrouve les attributs du
fichier. Pour chaque attribut, on retrouve les xattrs.

Il ne me reste donc plus qu'à reproduire tout cela en Rust.
Le développement en Rust

Pour le développement de ce programme, j'ai établi certaines limites. Je me suis concentré uniquement sur la lecture des
fichiers du pool qui sont en version 4. Ma version de BackupPC est la version 4, et j'ai migré l'intégralité du pool de
stockage depuis la version 3.
Je n'ai donc pas de données en version 3 pour tester mon programme.
Si vous souhaitez tester mon programme ou l'utiliser, sachez qu'il n'est pas compatible avec la version 3 de BackupPC,
ni avec la version 4 si votre pool est un mélange de versions V3 et V4.
Si le besoin se fait sentir plus tard, il sera toujours possible d'améliorer tout cela.
Les fichiers compressés
J'ai donc commencé par développer un programme qui, à partir d'un hash, est capable de décompresser un fichier de ce
pool. Pour décompresser un fichier BackupPC compressé avec zlib, j'ai choisi d'utiliser la bibliothèque flate2, qui
est une alternative Rust à la bibliothèque standard zlib.
La bibliothèque flate2 permet de décompresser un fichier en utilisant la notion de BufReader en Rust. La version
simplifiée pour décompresser un fichier du pool est donc la suivante :
use flate2::bufread::ZlibDecoder;
use std::fs::File;
fn main() {
let f = File::open("33fe8f9ae2f5cedbea63b9d3ea767ac0").unwrap();
let b = BufReader::new(f);
let mut z = ZlibEncoder::new(b);
let mut buffer = Vec::new();
z.read_to_end(&mut buffer).unwrap();
println!("{:?}", buffer);
}
Malheureusement, ce code ne fonctionne pas à tous les coups. Pour les plus petits fichiers de mon pool, cela fonctionne
très bien, mais quand on se retrouve avec les fichiers volumineux que BackupPC a décidé de découper, cela ne fonctionne
plus.
De plus, dans certains cas, BackupPC remplace certains octets
pour indiquer que l'on est au début d'un nouveau bloc de données zlib, ou pour indiquer que l'on a ajouté à la fin une
checksum md4.
Comme certains fichiers peuvent être volumineux, je ne peux pas faire un read_to_end pour lire le fichier en
mémoire et le modifier.
Le fichier bpc_fileZIO.c permet de comprendre
comment sont encodés les fichiers compressés.
Lors de la lecture d'un fichier compressé, si la lecture de la compression s'arrête et qu'il reste encore des octets
à lire, alors il faut recommencer une nouvelle décompression.
On peut aussi voir le bout de code suivant :
// https://github.com/backuppc/backuppc-xs/blob/master/bpc_fileZIO.c#L219C15-L237C18
if ( fd->strm.next_in[0] == 0xd6 || fd->strm.next_in[0] == 0xd7 ) {
/*
* Flag 0xd6 or 0xd7 means this is a compressed file with
* appended md4 block checksums for rsync. Change
* the first byte back to 0x78 and proceed.
*/
fd->strm.next_in[0] = 0x78;
} else if ( fd->strm.next_in[0] == 0xb3 ) {
/*
* Flag 0xb3 means this is the start of the rsync
* block checksums, so consider this as EOF for
* the compressed file. Also seek the file so
* it is positioned at the 0xb3.
*/
fd->eof = 1;
/* TODO: check return status */
lseek(fd->fd, -fd->strm.avail_in, SEEK_CUR);
fd->strm.avail_in = 0;
}
Si, en début de flux, on trouve 0xd6 ou 0xd7, il faut changer le premier octet en 0x78 et continuer la lecture. En
fin de flux, si on trouve 0xb3, on considère que c'est la fin du fichier compressé. (De notre côté, nous ne nous
intéresserons pas à la partie checksum md4).
La bibliothèque flate2 ne permet pas de faire cela simplement. J'ai donc dû lire le code de flate2 pour comprendre
comment je pouvais agir pour lire un fichier compressé de BackupPC.
Le code suivant de la bibliothèque flate2
permet de voir que flate2 a besoin, dans son constructeur, d'un BufRead pour lire un fichier compressé. Il utilise
la méthode fill_buf pour remplir un tampon et la méthode consume pour consommer le tampon.
// https://github.com/rust-lang/flate2-rs/blob/main/src/bufreader.rs#L73
impl<R: Read> Read for BufReader<R> {
fn read(&mut self, buf: &mut [u8]) -> io::Result<usize> {
// If we don't have any buffered data and we're doing a massive read
// (larger than our internal buffer), bypass our internal buffer
// entirely.
if self.pos == self.cap && buf.len() >= self.buf.len() {
return self.inner.read(buf);
}
let nread = {
let mut rem = self.fill_buf()?;
rem.read(buf)?
};
self.consume(nread);
Ok(nread)
}
}
J'ai donc commencé par développer un adaptateur qui s'intercale entre le fichier et le décompresseur. Cet adaptateur
a pour objectif de reproduire le comportement de BackupPC et de remplacer les octets en début de fichier.
struct InterpretAdapter<R: BufRead> {
inner: R,
first: bool,
temp: Option<Vec<u8>>,
}
impl<R: BufRead> InterpretAdapter<R> {
fn new(inner: R) -> Self {
Self {
inner,
first: true,
temp: None,
}
}
fn reset(&mut self) {
self.first = true;
self.temp = None;
}
}
...
impl<R: BufRead> BufRead for InterpretAdapter<R> {
fn fill_buf(&mut self) -> io::Result<&[u8]> {
if self.temp.is_none() {
let buf = self.inner.fill_buf()?;
let mut buf = buf.to_vec();
if self.first && !buf.is_empty() {
self.first = false;
if buf[0] == 0xd6 || buf[0] == 0xd7 {
buf[0] = 0x78;
} else if buf[0] == 0xb3 {
// EOF
buf = Vec::new();
}
}
self.temp = Some(buf);
}
Ok(self.temp.as_ref().unwrap())
}
fn consume(&mut self, amt: usize) {
if amt > 0 {
self.temp = None;
self.inner.consume(amt);
}
}
}
Cet adaptateur s'intercale entre le BufReader et le ZLibDecoder. Du point de vue du ZLibDecoder, il doit
se comporter comme un BufReader et donc implémenter les méthodes fill_buf et consume. Dans ces méthodes, je dois
retourner un tampon.
Je ne peux pas modifier directement le tampon du BufReader car ce dernier est une référence en lecture seule. Je
copie donc le contenu (je n'ai pas trouvé de meilleure manière de faire cela).
Enfin, on peut développer le Reader qui sera capable de lire les fichiers compressés. Pour cela, j'ai d'abord
implémenté une méthode read_some_bytes qui permet de lire un certain nombre d'octets. Si jamais on arrive à la fin
d'une section, alors la méthode peut retourner moins que la taille du tampon. Généralement, cela arrive en fin de
fichier. Quand j'ai utilisé directement cette méthode en tant que méthode read, je me suis retrouvé avec des
corruptions.
pub struct BackupPCReader<R: Read> {
decoder: Option<ZlibDecoder<InterpretAdapter<BufReader<R>>>>,
}
...
fn read_some_bytes(&mut self, buf: &mut [u8]) -> io::Result<usize> {
loop {
let decoder = self.decoder.as_mut();
if decoder.is_none() {
return Ok(0);
}
let decoder_read_result = decoder.unwrap().read(buf);
let count = match decoder_read_result {
Ok(count) => {
count
}
Err(e) => {
return Err(e);
}
};
if count != 0 {
return Ok(count);
}
if count == 0 {
let decoder = self.decoder.take();
if let Some(decoder) = decoder {
let mut reader = decoder.into_inner();
// S'il reste encore des octets à lire dans reader alors on continue, sinon on s'arrête
if reader.fill_buf()?.is_empty() {
return Ok(0);
}
reader.reset();
self.decoder = Some(ZlibDecoder::new(reader));
}
}
}
}
J'ai donc rédigé une méthode read qui remplit le tampon tant que le nombre d'octets lus est inférieur à la taille du
tampon. On ne retourne 0 que dans le cas où la lecture du fichier est terminée.
fn read(&mut self, buf: &mut [u8]) -> io::Result<usize> {
let mut total_bytes_read = 0;
while total_bytes_read < buf.len() {
let bytes_to_read = &mut buf[total_bytes_read..];
let bytes_read = self.read_some_bytes(bytes_to_read)?;
total_bytes_read += bytes_read;
if bytes_read == 0 {
break;
}
}
Ok(total_bytes_read)
}
Les fichiers d'attributs
Les fichiers d'attributs sont d'abord des fichiers compressés en utilisant la méthode décrite précédemment. J'ai donc
utilisé le Reader que j'ai écrit précédemment pour décompresser les fichiers au fur et à mesure de leur lecture.
Je me suis ensuite attaqué au décodage des fichiers d'attributs. En réécrivant le code, j'ai découvert que certains
nombres étaient mal encodés, ce qui provoquait des erreurs de décodage que j'ai dû gérer avec plus de flexibilité.
Pour lire un Varint, j'ai ajouté un trait au trait Read. Je me suis basé sur le code C de BackupPC,
tout en modifiant la philosophie pour répondre au fonctionnement d'un Reader Rust.
pub trait VarintRead: Read {
fn read_varint(&mut self) -> io::Result<u64> {
let mut result = 0;
let mut shift = 0;
loop {
let mut buf: [u8; 1] = [0u8; 1];
self.read_exact(&mut buf)?;
let byte = buf[0];
let val = (byte & 0x7F) as u64;
if shift >= 64 || val << shift >> shift != val {
eprintln!("Varint too large: probably corrupted data");
return Err(io::Error::new(
io::ErrorKind::InvalidData,
"Varint too large: probably corrupted data",
));
}
result |= val << shift;
if byte & 0x80 == 0 {
return Ok(result);
}
shift += 7;
}
}
}
Au cours de mes tests pour lire les fichiers d'attributs du pool, j'ai rencontré de nombreuses erreurs de décodage (avec
le message ci-dessus : Varint too large: probably corrupted data). Ce qui est rassurant, c'est que cela n'est pas lié
à mon algorithme. BackupPC rencontre le même problème lors du décodage de ses propres fichiers (ce qui se traduit dans
son cas par une date en janvier 1970) :
La question est donc : mes données sont-elles corrompues ou s'agit-il d'un bug de BackupPC ? Je ne vais pas obtenir de
réponse à cette question.
La lecture des machines et des sauvegardes
La partie la plus ardue est terminée.
- Pour lister les machines, il suffit de lister les dossiers du répertoire
__TOPDIR__/pc.
- Pour lister les sauvegardes, il faut lire le fichier texte (tsv)
__TOPDIR__/pc/<machine>/backups.
- Pour lister les dossiers partagés, il faut lister les dossiers du répertoire
__TOPDIR__/pc/<machine>/<backup>.
J'ai écrit ces trois méthodes dans ce fichier, que je vous invite à consulter. Il n'est pas très complexe : hosts.rs.
Je peux donc affirmer que j'ai réussi à lire les fichiers du pool de BackupPC. Pour mieux visualiser le résultat, j'ai
décidé de me lancer un défi supplémentaire : écrire un pilote FUSE pour visualiser le pool de stockage.
Le driver FUSE
L'étape suivante consiste donc à développer un pilote FUSE qui intègre tout cela. Il s'agit de lire les fichiers
d'attributs pour reconstituer la structure du système de fichiers (qui sont dans le pool et compressés), et de lire les
fichiers compressés pour les données.
Pour gérer la partie du système de fichiers, j'ai utilisé la bibliothèque fuser.
Le cœur du système ayant été développé, la partie système de fichiers consiste principalement à décoder le chemin fourni
par FUSE, à décompressé et lire le fichier d'attributs. Dans le cas où l'utilisateur souhaite lire le contenu d'un
fichier, il faut décompresser le fichier compressé.
J'ai donc la partie système de fichiers qui gère les requêtes FUSE et les transmet à la partie vue (avec un système de
cache), et la partie vue qui prend un chemin et le transforme dans le format suivant en appelant les différentes
méthodes précédentes :
- nom de l'hôte
- numéro de sauvegarde
- chemin du partage
- chemin
Le décodage est réalisé dans le fichier view.rs.
Pour cette partie, j'ai ajouté des tests unitaires. Ces tests unitaires m'ont permis d'itérer plus rapidement pour
construire le système de fichiers (sans avoir à monter ce dernier à chaque fois).
On appelle la méthode avec le chemin découpé à chaque / pour obtenir les différents éléments du chemin (sous forme de
&[&str]).:
pub fn list(&self, path: &[&str]) -> Result<Vec<FileAttributes>> {
match path.len() {
On commence d'abord par examiner le nombre d'éléments dans le chemin. Si nous n'avons aucun élément, cela signifie que
nous sommes à la racine et que nous souhaitons obtenir la liste des machines.
0 => {
let hosts = self.hosts.list_hosts()?;
Ok(hosts.into_iter().map(FileAttributes::from_host).collect())
}
Si nous avons un seul élément, alors c'est le nom de la machine. Nous souhaitons donc récupérer la liste des sauvegardes
associées à cette machine.
1 => {
let backups = self.hosts.list_backups(path[0]);
match backups {
Ok(backups) => Ok(backups
.into_iter()
.map(|a| FileAttributes::from_backup(&a))
.collect()),
Err(err) => {
// If the file isn't found, it's because we should return empty vec
if let Some(io_err) = err.downcast_ref::<std::io::Error>() {
if io_err.kind() == std::io::ErrorKind::NotFound {
Ok(Vec::new())
} else {
Err(err)
}
} else {
Err(err)
}
}
}
}
Si nous avons plus de deux éléments, alors nous souhaitons retourner au moins le partage, voire les fichiers à
sauvegarder. Le problème est que le nom du partage share peut lui-même contenir des /. Il peut donc être composé de
plusieurs éléments.
Le but de la méthode list_shares_of est de retourner le partage si ce dernier est un partage valide, ainsi que la
partie du chemin qui suit le partage.
_ => {
let (shares, selected_share, share_size) =
self.list_shares_of(path[0], path[1].parse::<u32>().unwrap_or(0), &path[2..])?;
let shares = shares.into_iter().map(FileAttributes::from_share).collect();
Une fois que nous avons le nom de la machine, le numéro de la sauvegarde et le partage, nous pouvons appeler la méthode
list_file_from_dir pour récupérer les fichiers du sous-dossier du partage.
match selected_share {
None => Ok(shares),
Some(selected_share) => self.list_file_from_dir(
path[0],
path[1].parse::<u32>().unwrap_or(0),
&selected_share,
&path[(2 + share_size)..].join("/"),
),
}
}
}
}
Enfin, pour la partie FUSE, je vous invite à consulter le fichier filesystem.rs.
Ce fichier fait simplement le lien entre la partie FUSE et la partie vue.
Sur la partie FUSE, j'ai ajouté un cache pour éviter de lire plusieurs fois le même fichier (d'attributs) dans le pool.
Une fois le système de fichiers construit, il était nécessaire de le tester avec des tests réels. Le premier test a
consisté à parcourir l'ensemble du système de fichiers pour vérifier si la partie attribut fonctionnait correctement.
Pour cela, j'ai utilisé le programme filelight. Ce programme permet de parcourir le système de fichiers et de
visualiser la taille des fichiers.
Voici un exemple sur une partie de la sauvegarde :
Enfin, pour tester la capacité du programme à lire tous les fichiers du système de fichiers, j'ai écrit un petit script
shell.
#!/bin/bash
# Fichiers de sortie
output_file="md5sums.txt"
error_file="errors.txt"
# Parcourir tous les fichiers du système de fichiers
find /home/phoenix/tmp/test -type f -print0 | while IFS= read -r -d '' file; do
# Essayer de calculer le hash MD5 du fichier
if md5sum "$file" >> "$output_file"; then
echo "Processed $file"
else
# Si le fichier ne peut pas être lu, écrire le nom du fichier dans le fichier d'erreur
echo "Failed to process $file" >> "$error_file"
fi
done
J'ai récemment commencé à développer un autre programme en Rust qui utilise la notion de multithreading.
Les avantages de Rust
En travaillant sur ce petit programme Rust, j'ai apprécié plusieurs aspects du langage. Rust offre la possibilité
d'écrire du code de bas niveau sans avoir à gérer la mémoire comme en C, ce qui m'a procuré un sentiment de sécurité. De
plus, la documentation de Rust est bien conçue et m'a permis de progresser rapidement.
J'ai également trouvé la syntaxe de Rust très lisible, à condition de ne pas utiliser les durées de vie. La présence de
nombreux packages (crates) sur crates.io facilite le développement rapide de fonctionnalités.
Clippy, un outil de vérification du code Rust, m'a été très utile. Il donne des conseils pour améliorer le code, ce qui
m'a aidé à progresser, même s'il me reste encore du chemin à parcourir.
Les défis rencontrés avec Rust
Malgré ces avantages, j'ai rencontré quelques difficultés, probablement dues à ma méconnaissance du langage Rust. Par
exemple, pour certaines parties du code, je me suis retrouvé avec du code contenant le mot unsafe. J'ai refusé de
l'utiliser, ce qui a rendu mon code plus complexe.
J'ai un cas particulier pour lequel je n'ai pas trouvé de solution. Dans mon logiciel de sauvegarde, je lis des noms de
fichier que je stocke en tant que [u8] en Protobuf dans un fichier. Si je traite ces noms de fichier en tant que
chaîne de caractères, je me retrouve avec des erreurs potentielles de conversion si le nom de fichier n'est pas en UTF-8
sous Linux et en UTF-16 sous Windows. Pour stocker donc sous forme d'octet, j'utilise ces méthodes qui m'obligent à
utiliser unsafe :
#[must_use]
pub fn osstr_to_vec(path: &OsStr) -> Vec<u8> {
path.as_encoded_bytes().to_vec()
}
#[must_use]
pub fn vec_to_osstr(vec: &[u8]) -> OsString {
unsafe { OsString::from_encoded_bytes_unchecked(vec.to_owned()) }
}
Le problème est que dans l'interface, des noms Windows ou Linux peuvent être affichés. Je ne souhaite pas que le
programme plante, mais qu'au pire des cas, il affiche un nom de fichier incorrect. Je ne suis pas sûr que le code écrit
soit la meilleure solution. (D'après mes tests, il fonctionne). Une meilleure solution pour convertir un OsStr en
String en fonction de l'encodage actuel (la variable d'environnement LANG sous Linux) aurait été pratique.
La gestion de la mémoire, bien que semblant simple au premier abord, devient rapidement complexe lorsqu'on veut faire du
multithreading. On se retrouve à mettre des structures dans des Box, des Mutex et des Arc, ce qui complique la syntaxe.
L'introduction de dynamisme, notamment pour la gestion des erreurs, nécessite l'utilisation du mot-clé dyn, ce qui
peut également devenir complexe. Je me retrouve avec presque toutes mes méthodes qui retournent un
Result<???, Box<dyn Error>>. Là aussi, je me demande si c'est une bonne pratique.
De plus, Rust semble souvent nous obliger à cloner des objets, alors que j'aurais parfois préféré utiliser simplement la
référence de l'objet. Mais comme potentiellement Rust n'arrive pas à déterminer si dans un cas de multithreading la
variable sera toujours valide, on doit la cloner. Parfois dans ces cas, je me dis qu'en C, je sais quand j'alloue, quand
je désalloue, qui a le droit de lire et d'écrire. De mes souvenirs du C et du C++, j'avais plus de contrôle, le code me
paraissait plus facile à écrire. Maintenant, le moindre oubli, petite erreur, peut être fatal, et Rust nous protège de
cela. Bref, je pense simplement que je dois encore prendre le temps de me familiariser avec la philosophie de Rust.
Enfin, les erreurs de compilation ont été un gros défi. J'ai passé des heures à essayer de comprendre certaines erreurs,
à ajuster les durées de vie ou à ajouter static, Send, Sync ou Clone sans savoir quelle était la bonne façon de
faire.
Les tests unitaires
J'ai réalisé des tests unitaires pour une partie du développement. Cependant, l'écriture de ces tests a été difficile,
surtout en comparaison avec des bibliothèques comme Jest en JavaScript.
La création de mocks pour les interfaces et les autres fichiers n'est pas native à Rust et n'est pas une tâche simple.
J'ai dû utiliser une bibliothèque dédiée, mockall.
L'utilisation de mocks m'a contraint à créer des structures, alors qu'initialement j'avais des méthodes. J'ai commencé
avec des méthodes statiques, mais leur gestion avec les mocks ne permet pas de réaliser des tests unitaires en
parallèle. Pour exécuter les tests unitaires, j'ai dû lancer un test à la fois avec la commande
RUST_TEST_THREADS=1 cargo test.
Cependant, j'ai réussi à modifier les tests unitaires pour qu'ils puissent s'exécuter en parallèle sans supprimer les
méthodes statiques.
Conclusion
Maintenant que j'ai écrit ce petit programme, je vais pouvoir créer mon propre pool de stockage. De votre côté,
n'hésitez pas à me faire des retours sur le programme. Je suis ouvert à toutes les critiques. De plus, si vous utilisez
BackupPC (en version 4 uniquement et avec un pool de stockage en version 4), vous pouvez tester mon programme et
l'utiliser.



















